Ollama
Ollamaを使用してLLMをセルフホストする方法を学びます。
現在LLMのセルフホストはProプランでのプレビュー機能です。使用を希望される場合はダッシュボード上からProプランに更新の上ウェイトリストにお申し込みください。
SquadbaseではOllamaによるLLMのセルフホスト機能を提供しています。 ダッシュボード上で使用したいモデルを選択しデプロイすることでAPIとして呼び出し可能なURLが発行されPythonのコード上から呼び出すことができます。
LLMをセルフホストする
LLMをデプロイする
ダッシュボードのLLMタブを押下しLLM作成画面に遷移します。
任意のLLM Nameを入力し、使用するModel Nameを選択します。
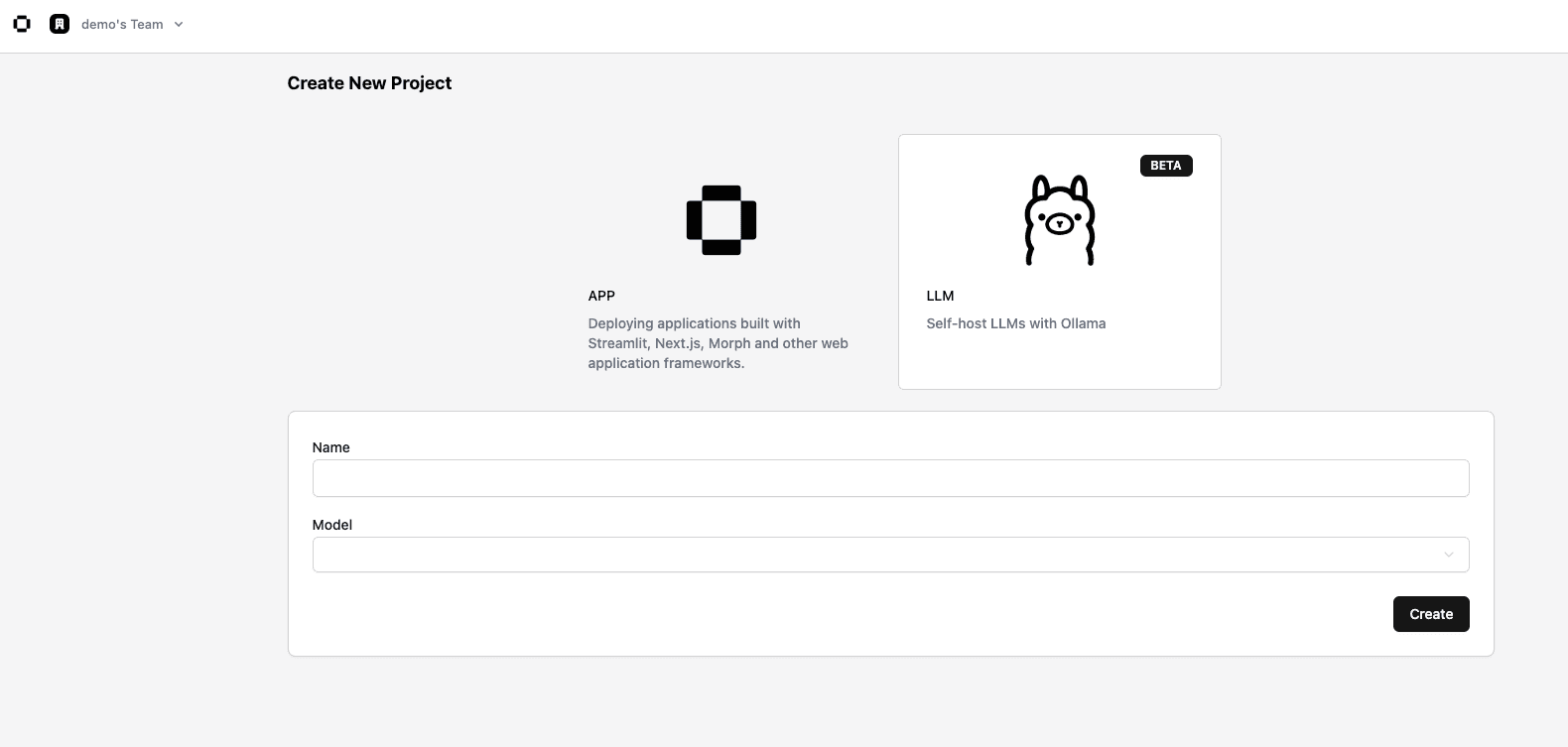
現在以下のモデルが使用可能です。
| Model | Parameters |
|---|---|
deepseek-r1 | 1.5b, 7b, 8b, 14b |
llama3.2 | 8b |
phi4 | 14b |
qwen | 0.5b, 1.8b, 4b, 7b, 14b |
作成したモデルを確認する
LLMタブから作成したLLMを選択します。
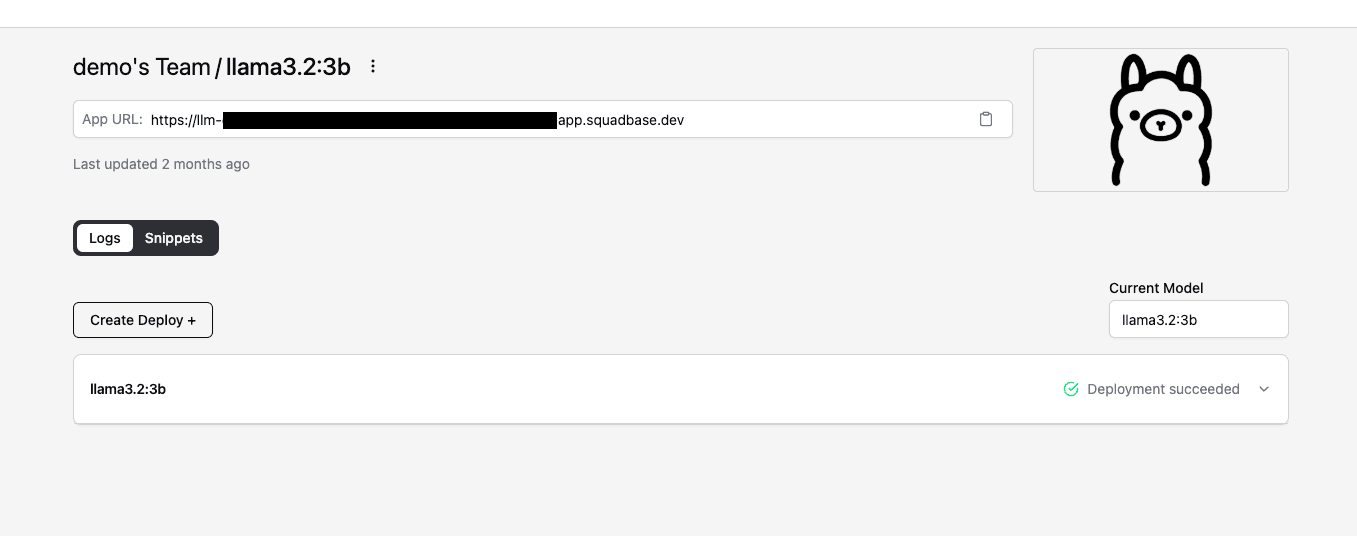
Logsの欄で選択したモデルのステータスがDeployment Succeededであれば作成が成功しています。まだ進行中の場合は作成完了までお待ちください。
App URLはSquadbaseにホストされたLLMのURLです。このURLとSquadbaseのAPI Keyを使用してLLMにリクエストを送ることが可能です。
LLMにリクエストを送る
先ほどのApp URLとSquadbaseのAPI Keyを使用してLLMにリクエストを送ります。
以下はPythonとcURLによるリクエストのサンプルです。
Pythonで使用する場合はlangchain-ollamaパッケージをインストールする必要があります。
pip install langchain-ollamapoetry add langchain-ollamauv add langchain-ollamafrom langchain_ollama import ChatOllama
llm = ChatOllama(
model="{MODEL_NAME_YOU_DEPLOYED}",
base_url="{YOUR_SQUADBASE_LLM_APP_URL}",
client_kwargs={
"headers": {
"x-api-key": "{YOUR_SQUADBASE_API_KEY}",
}
},
)
for token in llm.stream("Hello"):
yield token.contentcurl --location ‘{YOUR_SQUADBASE_LLM_APP_URL}/api/chat' \
--header 'Content-Type: application/json' \
--header 'x-api-key: {YOUR_SQUADBASE_API_KEY}’ \
--data '{
"model": "{MODEL_NAME_YOU_DEPLOYED}",
"messages": [
{
"role": "user",
"content": “Hello”
}
]
}'